How I Connected Postgres & Supabase to n8n to Build Smarter AI Agents
When I first started experimenting with AI agents in n8n, I kept running into the same problem: my agents had no memory. They could respond in the moment, but once the conversation was over, they forgot everything.
I wanted something more. I wanted agents that could:
That’s when I decided to connect Postgres and Supabase to n8n. Here’s the story of how it all came together.
Setting the Goal 🎯
The plan was simple:
If I could pull this off, my agent would be able to both remember chats and answer questions based on real documents.
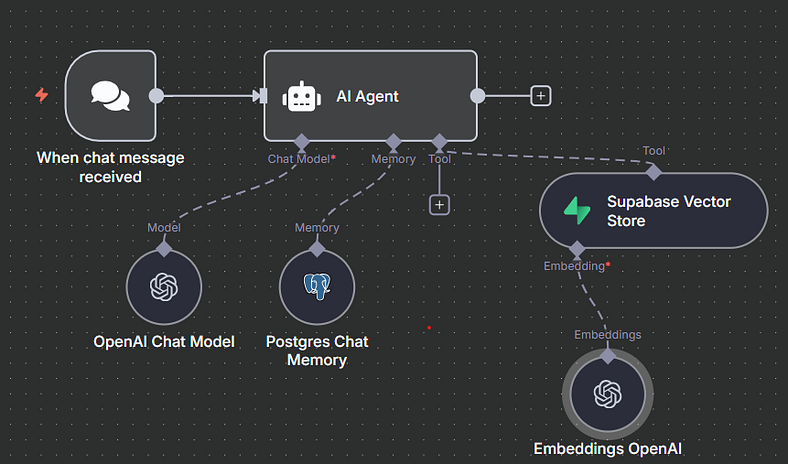
Step 1: Setting Up Supabase
I started by creating a Supabase account. Once signed in, I spun up a new organization and then a project. Supabase asked me for a project password, so I made sure to save it — I knew I’d need it later for my connection credentials.
At first, Supabase greeted me with a ton of confusing API keys and secrets. It wasn’t clear what belonged where. But after some digging, I found exactly what I needed under Database → Connect:
Those four details would become the foundation of my Postgres credential inside n8n.
Step 2: Connecting Postgres to n8n
Back in n8n, I added a Postgres Chat Memory node. I plugged in the host, username, password, and port I had just gathered from Supabase.
The connection went green ✅. That was a good sign.
To test it, I fired up a quick chat:
I checked my Postgres chat memory table in Supabase, and sure enough — both my message and the agent’s reply were stored, tied together by a unique session ID.
The agent finally had memory.
Step 3: Setting Up Supabase as a Vector Store
Now it was time for the RAG (retrieval-augmented generation) piece. For that, I needed Supabase not just as a database, but as a vector store.
In Supabase, I ran a quick SQL command from their docs to set up a new table called documents. This would be the home for all my vectorized data.
Then, I grabbed two key pieces of info from Project Settings → API:
With those in hand, I created a new Supabase Vector Store credential inside n8n. Again, the connection went green ✅.
Step 4: Putting Data Into Supabase
To make sure everything was working, I decided to upload a Google Doc into the vector store.
I grabbed a sample document —The Rules of Golf — Simplified — and ran it through a workflow:
n8n split the file into chunks, embedded them, and inserted them into Supabase. When I checked the table, the data was there — along with vector embeddings and metadata.
Step 5: Testing the Agent
Now came the fun part: testing the AI agent.
I asked: “what the document is about”
Here’s what happened behind the scenes:
The response?
“The document titled “The Rules of Golf — Simplified” is a simplified and paraphrased version of the official Rules of Golf as published by the United States Golf Association and the R&A Rules Limited”
When I cross-checked, those exact details were sitting inside my Body Shop doc. The workflow worked like magic.
The Takeaway 💡
By combining Postgres and Supabase inside n8n, I had built an agent that could:
And the best part? It all ran in a no-code/low-code environment.
For me, this was a huge leap forward in building practical, scalable AI agents. Instead of stateless bots, I now had workflows that could think, remember, and reference knowledge.
👉 Next, I plan to expand this setup by experimenting with multiple document types, fine-tuned embeddings, and more complex memory strategies.
Have you tried connecting n8n with vector databases yet? If so, what’s your stack?