Building a RAG Agent with Metadata, Supabase, and Re-Ranking in n8n 🚀
Retrieval-Augmented Generation (RAG) has become a game-changer in AI applications. Instead of relying solely on an LLM’s training data, we can connect external knowledge sources, vectorize them, and retrieve the most relevant information when a user asks a question.
In this article, I’ll walk you through how I set up a Metadata-powered RAG Agent using Supabase, OpenAI, Cohere, and n8n — a no-code/low-code automation platform. By the end, you’ll see how we can build an end-to-end system that takes documents, adds metadata, vectorizes them, and delivers context-rich answers.
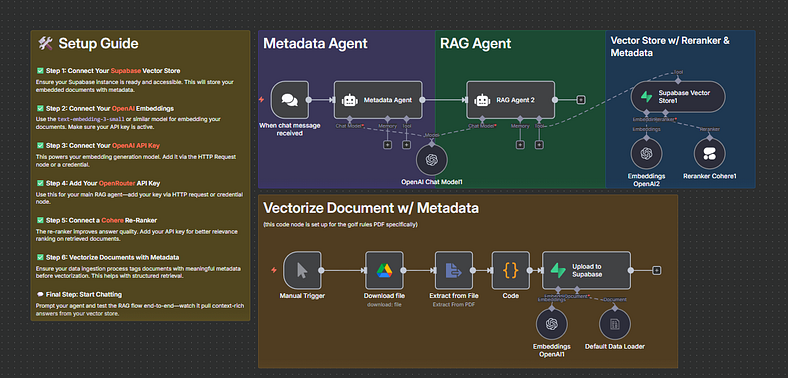
🛠️ Setup Guide
Before diving into the workflow, here’s what you need to configure:
Connect Your Supabase Vector Store Supabase will serve as the database for storing embedded documents along with their metadata. Ensure your Supabase instance is live and accessible.
Connect Your OpenAI Embeddings Use text-embedding-3-small (or any similar model) to generate vector embeddings of your documents.
Connect Your OpenAI API Key This powers the embedding generation. Make sure you load your API key into n8n using HTTP Request or Credential nodes.
Add Your OpenRouter API Key This key will be used to handle requests for your main RAG agent. It ensures LLM access for contextual answering.
Connect a Cohere Re-Ranker To improve the quality of retrieved documents, a re-ranker ensures the most relevant chunks surface to the top.
Vectorize Documents with Metadata Metadata tagging (like titles, sections, categories) makes retrieval more structured and accurate. This step ensures the agent has context beyond raw text.
✅ Once all this is ready, you can start chatting with your RAG Agent.
Want to Lear more: Join the Free Skool community :
https://www.skool.com/ai-university-4881/aboutref=a5e04c95f0fc4a20a985370a705cbef5
🤖 Metadata Agent + RAG Agent Flow
Here’s the heart of the system:
This flow ensures every answer is context-aware and backed by structured knowledge.
📄 Vectorizing Documents with Metadata
For this article, I set up a pipeline for processing PDFs (Golf Rules example):
Manual Trigger — Start the process on demand.
Download File — Fetch the PDF document.
Extract from File — Convert PDF into structured text.
Code Node — Clean and prepare text, attach metadata.
Upload to Supabase — Store embeddings + metadata inside the vector database.
Now, every new document you process becomes part of the knowledge base that your RAG Agent can access.
🌟 Why Metadata Matters
Most RAG setups simply chunk text and embed it. But when you add metadata, the retrieval becomes far smarter. For example:
This makes your AI assistant much closer to a real expert rather than a random text retriever.
🎯 Final Thoughts
By combining Supabase (storage), OpenAI (embeddings + LLM), Cohere (re-ranking), and n8n (workflow automation), we can build a robust end-to-end RAG system without writing thousands of lines of backend code.
This architecture is flexible and scalable — you can apply it to legal documents, product manuals, company wikis, or research papers.
💡 Next step? Automate ingestion of multiple documents and let your RAG agent become your AI knowledge assistant.